Data Studios
View all mounted datasets
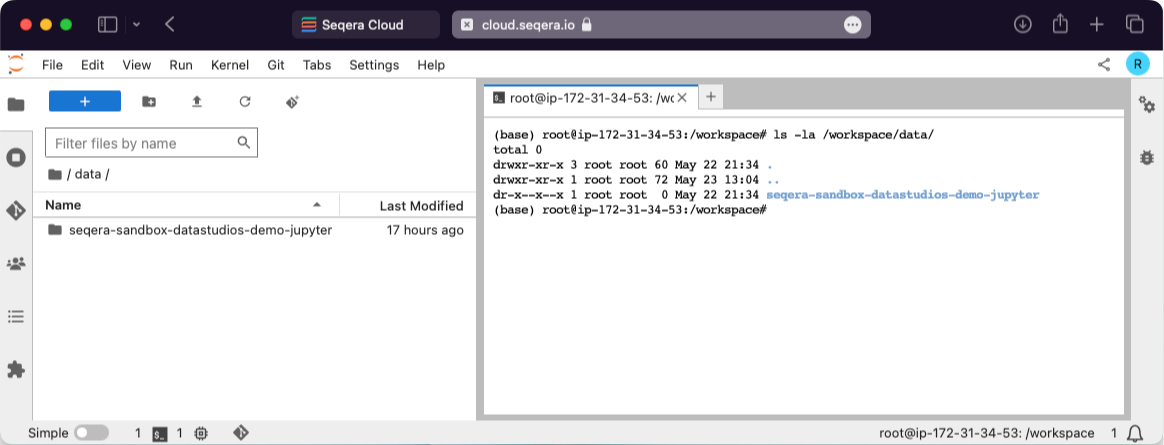
In your interactive analysis environment, open a new terminal and type ls -la /workspace/data. This displays all the mounted datasets available in the current studio session.
Data Studio session is stuck in starting
If your studio session doesn't advance from starting status to running status within 30 minutes, and you have access to the AWS Console for your organization, check that the AWS Batch compute environment associated with the data studio session is in the ENABLED state with a VALID status. You can also check the Compute resources settings. Contact your organization's AWS administrator if you don't have access to the AWS Console.
If sufficient compute environment resources are unavailable, Stop the studio session and any others that may be running before trying again. If you have access to the AWS Console for your organization, you can terminate a specific session from the AWS Batch Jobs page (filtering by compute environment queue).
Data Studio session status is errored
The errored status is generally related to issues encountered when creating the studio session resources in the compute environment (e.g., invalid credentials, insufficient permissions, network issues). It can also be related to insufficient compute resources, which are set in your compute environment configuration. Contact your organization's AWS administrator if you don't have access to the AWS Console. Also contact your Seqera account executive so we can investigate the issue.
Data Studio session can't be stopped
If you're not able to stop a studio session, it's usually because the Batch job running the session failed for some reason. In this case, and if you have access to the AWS Console for your organization, you can stop the session from the compute environment screen. Contact your organization's AWS administrator if you don't have access to the AWS Console. Also contact your Seqera account executive so we can investigate the issue.
Data Studio session performance is poor
A slow or unresponsive studio session may be due to its AWS Batch compute environment being utilized for other jobs, such as running Nextflow pipelines. The compute environment is responsible for scheduling jobs to the available compute resources. Data Studio sessions compete for resources with the Nextflow pipeline head job and Seqera does not currently have an established pattern of precedence.
If you have access to the AWS Console for your organization, check the jobs associated with the AWS Batch compute environment and compare the resources allocated with its Compute resources settings.
Memory allocation of the Data Studio session is exceeded
The running container in the AWS Batch compute environment inherits the memory limits specified by the studio session configuration when adding or starting the session. The kernel then handles the memory as if running natively on Linux. Linux can overcommit memory, leading to possible out-of-memory errors in a container environment. The kernel has protections in place to prevent this, but it can happen, and in this case, the process is killed. This can manifest as a performance lag, killed subprocesses, or at worst, a killed data studio session. Running studio sessions have automated snapshots created every five minutes, so if the running container is killed only those changes made after the prior snapshot creation will be lost.
All datasets are read-only
By default, AWS Batch compute environments that are created with Batch Forge restrict access to S3 to the working directory only, unless additional Allowed S3 Buckets are specified. If the compute environment does not have write access to the mounted dataset, it will be mounted as read-only.